
2025-8月论文阅读
On the Feasibility of Cross-Language Detection of Malicious Packages in npm and PyPI
{2023}, {Piergiorgio Ladisa, Serena Elisa Ponta, Nicola Ronzoni, Matias Martinez, Olivier Barais}, {ACSAC'23}
Key Points
- 跨语言恶意包检测
- \(GL_4\)
- XGBoost
- 香农熵
Summary
本文聚焦 npm(JavaScript)和 PyPI(Python)生态的开源供应链恶意包检测问题,针对现有机器学习方法多局限于单语言、样本稀缺的痛点,提出基于语言无关特征的跨语言检测方案。作者首先构建包含恶意样本(来自 BKC,去重后共 194 个)和良性样本(来自 libraries.io 流行包,共 1640 个)的单语言与跨语言数据集,提取 141 个语言无关特征(如安装钩子使用、字符串香农熵统计、GL₄编码后的同质 / 异质字符串计数等);随后用 DT、RF、XGBoost 训练模型,通过 5 折交叉验证发现 XGBoost 在精确率与召回率间平衡最佳;最后通过 10 天扫描 npm/PyPI 新包的真实实验,识别出 58 个未知恶意包并补充到 BKC,验证了跨语言检测的可行性 —— 跨语言模型在 npm 生态误报更少,在 PyPI 生态能多识别真正例,为缓解单语言样本稀缺问题提供了新思路。
Research Objective(s)
- 验证 “捕捉 JavaScript 与 Python 恶意包共性、实现跨语言检测” 的可行性;
- 对比单语言与跨语言模型,找到在精确率和召回率间平衡最优的模型(回答 RQ1);
- 评估最优模型在真实场景(新上传包)的恶意检测性能(回答 RQ2);
- 克服单语言检测中样本稀缺的挑战,扩展恶意包检测的覆盖范围。
Background / Problem Statement
当前开源供应链高度依赖 npm、PyPI 等公共仓库,恶意用户通过发布含恶意代码的包大规模传播 malware;现有机器学习检测方法多针对单语言(如仅 npm),且依赖的标注数据集(如 BKC)样本量少;尽管 JavaScript 与 Python 语法不同,但两者恶意包存在共性(如利用安装脚本、含混淆字符串 / URL)。
Problem Statement
- 单语言检测模型受限于样本稀缺,难以扩展到多生态;
- 缺乏基于语言无关特征的跨语言检测方案,无法利用多语言样本提升检测能力;
- 现有方法需验证在真实场景(新上传包)的有效性,尤其是精确率(减少误报以降低人工审核成本)
Method(s)
- 数据集构建
- 恶意样本:来自 BKC,去重(过滤多版本、同 campaign、特征重复样本)后保留 npm102 个、PyPI92 个;
- 良性样本:从 libraries.io 选流行包(按 SourceRank 排序),按 90:10(良性:恶意)比例取 npm918 个、PyPI828 个;
- 数据集类型:2 个单语言数据集(仅 npm / 仅 PyPI)、1 个跨语言数据集(npm+PyPI)。
- 特征提取
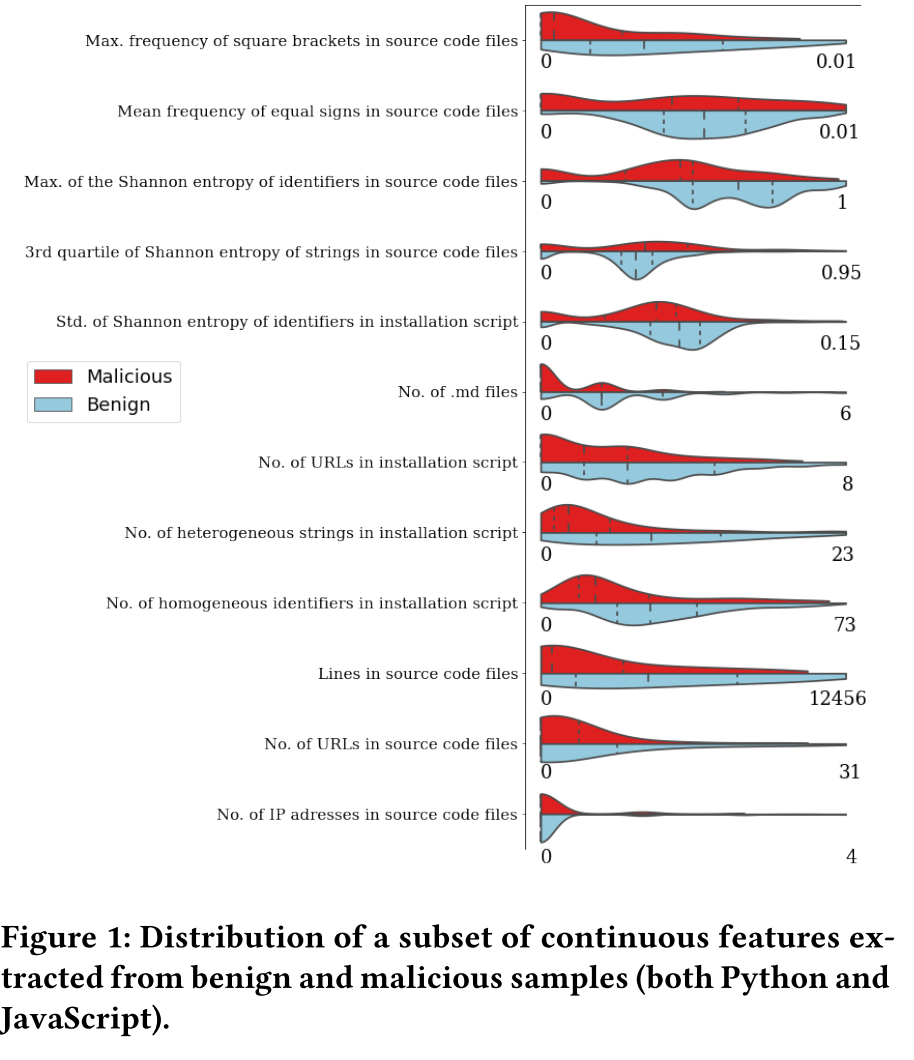
- 141 个语言无关特征,涵盖 4 类:安装钩子使用(如 setup.py、package.json 的 preinstall 脚本)、代码混淆特征(字符串 / 标识符的香农熵均值 / 标准差 / 3rd 四分位数 / 最大值、GL₄编码后的同质 / 异质计数)、敏感字符串(URL/IP/Base64 字符串计数)、包结构特征(文件行数、特定扩展名文件数)。
- 模型训练与优化
- 算法:选择 DT、RF、XGBoost(适配不平衡数据集、可解释、支持高维特征);
- 调参:用贝叶斯优化(BO)+5 折交叉验证,以精确率为目标函数优化超参数。
- 评估方法
- 受控实验:5 折交叉验证(分层抽样保持 90:10 比例),评估精确率、召回率、F1、准确率;
- 真实实验:10 天(2022.10.24-11.2)扫描 npm/PyPI 新包,手动审核模型标记的恶意包以确认 TP/FP。
是否基于前人的方法?基于了哪些?
- 基于 Sejfia et al. [30] 和 Ohm et al. [24] 的部分特征(如安装钩子、敏感字符串),但扩展为语言无关特征;
- 采用 BKC 数据集(前人常用的恶意包数据集),并优化样本去重逻辑;
- 借鉴前人用 DT、RF 检测恶意包的经验,新增 XGBoost 算法验证;
- 参考 Ohm et al. [24] 的 90:10 良性 - 恶意样本比例设置。
Evaluation
作者如何评估自己的方法?
- 分两步:先通过受控实验(5 折交叉验证)对比单语言 / 跨语言模型的性能,筛选最优模型;再通过真实实验(10 天新包扫描)验证最优模型在实际场景的有效性。
数据集、基线模型
- 数据集:
- 受控实验:单语言数据集(npm:102 恶意 + 918 良性;PyPI:92 恶意 + 828 良性)、跨语言数据集(194 恶意 + 1640 良性);
- 真实实验:31292 个新包(npm+PyPI,10 天内上传)。
- 基线模型:DT、RF、XGBoost 的单语言(仅 npm / 仅 PyPI)与跨语言(npm+PyPI)模型,共 9 个模型。
感兴趣实验数据和结果有哪些?
- 受控实验(5 折交叉验证)
- XGBoost 表现最优:npm 单语言模型 F1 84.4%、PyPI 单语言模型 F1 68.0%;跨语言模型在 PyPI 场景略优于单语言(F1 66.9% vs 68.0%,差距小);
- DT 精确率高但召回率低(如 PyPI 单语言 DT 精确率 81.6%、召回率 28.9%),实用性差。
- 真实实验
- 共识别 58 个未知恶意包(npm38 个、PyPI20 个),均被仓库移除并补充到 BKC;
- 跨语言 vs 单语言:npm 场景两者精确率均 3.1%(跨语言 FP 少 146 个、TP 少 1 个);PyPI 场景跨语言 TP 多 2 个,但 FP 多 598 个,精确率降至 1.4%(单语言 3.1%)。
- 特征有效性
- 安装钩子、Markdown 文件数量是关键特征:81% 的 npm 恶意包用安装钩子(良性包仅 2%),恶意包含 Markdown 文件比例远低于良性包(npm25% vs 82%)。
有没有问题或者可以借鉴的地方?
- 问题:
- 模型依赖 BKC 样本,仅能检测已知恶意行为(如反向 Shell、数据窃取),无法识别新类型恶意包(如克隆良性包注入单条恶意代码);
- 未评估召回率(未审核模型标记的良性包,无法确定漏检数);
- PyPI 跨语言模型 FP 过高,泛化能力待提升。
- 借鉴:
- 语言无关特征设计可复用(无需维护语言特定 API 列表);
- 跨语言训练能缓解样本稀缺,适合小生态检测;
- 真实场景长期扫描 + 手动审核的验证方式,提升结论可信度。
Conclusion
- 模型性能:XGBoost 在单语言和跨语言场景中,均实现精确率与召回率的最佳平衡,是最优模型;
- 跨语言可行性:JavaScript 与 Python 恶意包的共性(安装钩子、混淆字符串)支持跨语言检测,跨语言模型在真实场景有效,共识别 58 个未知恶意包;
- 特征价值:安装钩子、Markdown 文件数量、字符串香农熵等语言无关特征,能有效区分恶意与良性包;
- 扩展潜力:方法可移植到支持安装钩子的生态(如 RubyGems、Composer)。
Thought(s)
- 扩展生态与恶意类型:将方法扩展到 Ruby、PHP 生态,验证跨语言通用性;针对 “克隆良性包注入恶意代码” 等新类型,设计代码增量对比特征;
- 特征与模型优化:结合动态分析(如沙箱执行)补充静态特征,减少 FP;引入作者信誉、包更新频率等非代码特征,提升检测鲁棒性;
- 召回率评估与改进:设计大规模良性包抽样审核方案,量化模型召回率;采用半监督学习利用未标注数据,提升对新恶意类型的检测能力;
- 工程化落地:优化模型推理速度,适配仓库实时扫描场景;设计分级告警机制(如高风险包优先人工审核),降低运营成本。
Notes
本文使用Pgments词法分析器来解析和处理被分析软件包的源代码文件(.js,.py)以及安装脚本(package.json,setup.py)。从这些文件中,我们提取以下类型的词法标记:字符串、标识符、运算符和标点符号。
针对代码混淆方面,本文使用香农熵+泛化语言(GL)解决,因为可能一个恶意软件包中,大部分代码经过GL编码后的熵值低,但是某些恶意代码块编码后熵值高(经过Base64编码后)
针对敏感字符串方面,本文通过构建攻击性安全备忘录(例如,反向 shell、敏感文件路径)中构建一个关键词字典。这些关键词既包含纯文本形式,也包含不同的编码形式(例如,base64、base32、rot-13、URL 编码)。相应的特征是命中该字典的次数。
本文中的图一是相对来说在其他论文中没怎么见到过的一种图形式——小提琴图,论文通过这类分布图,筛选出 “恶意包和良性包差异最显著” 的特征(如 “安装脚本中的 URL 数量”“标识符香农熵”),作为后续机器学习模型的输入(比如用这些特征训练分类器,区分恶意 / 良性包)。
5 折交叉验证就是把数据集拆成 5 份,循环用 4 份训练、1 份测试,最后平均结果 ,目的是让模型评估更稳定、更可信,是论文 / 项目里证明模型有效性的 “标配操作”~
References
香农熵
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, Olivier Barais, and Serena Elisa Ponta. 2022. Towards the Detection of Malicious Java Packages. In Proceedings of the 2022 ACMWorkshop on Software Supply Chain Offensive Research and Ecosys- tem Defenses (Los Angeles, CA, USA) (SCORED’22). Association for Computing Machinery, New York, NY, USA, 63–72. https://doi.org/10.1145/3560835.3564548
泛化语言(GL)
Zhipeng Huang and Yeye He. 2018. Auto-Detect: Data-Driven Error Detection in Tables. In Proceedings ofthe 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD ’18). Association for Computing Machinery, New York, NY, USA, 1377–1392. https://doi.org/10.1145/3183713.3196889
攻击性安全备忘录
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, Olivier Barais, and Serena Elisa Ponta. 2022. Towards the Detection of Malicious Java Packages. In Proceedings of the 2022 ACMWorkshop on Software Supply Chain Offensive Research and Ecosys- tem Defenses (Los Angeles, CA, USA) (SCORED’22). Association for Computing Machinery, New York, NY, USA, 63–72. https://doi.org/10.1145/3560835.3564548
良性样本和恶性样本比例也有影响
Marc Ohm, Felix Boes, Christian Bungartz, and Michael Meier. 2022. On the Feasibility of Supervised Machine Learning for the Detection of Malicious Soft- ware Packages. In Proceedings ofthe 17th International Conference on Availability, Reliability and Security. 1–10.
结合代码复现器和简单克隆检测器的监督学习方法,用于 npm 中恶意软件包的自动检测
Adriana Sejfia and Max Schäfer. 2022. Practical Automated Detection ofMalicious npm Packages. arXiv preprint arXiv:2202.13953 (2022).
利用监督学习技术检测恶意软件包的可行性
Marc Ohm, Felix Boes, Christian Bungartz, and Michael Meier. 2022. On the Feasibility of Supervised Machine Learning for the Detection of Malicious Soft- ware Packages. In Proceedings ofthe 17th International Conference on Availability, Reliability and Security. 1–10.
通过无监督签名生成来检测恶意包活动的方法,该方法基于代码重用。具体来说,他们从 npm 包中生成抽象语法树(AST),并将它们聚类,以便识别具有共同特征的包。
Marc Ohm, Lukas Kempf, Felix Boes, and Michael Meier. 2020. If You’ve Seen One, You’ve Seen Them All: Leveraging AST Clustering Using MCL to Mimic Expertise to Detect Software Supply Chain Attacks. CoRR abs/2011.02235 (2020). arXiv:2011.02235 https://arxiv.org/abs/2011.02235
一种通过分析法证文物来检测恶意 JavaScript 和 Python 包的动态分析方法。
Marc Ohm, Arnold Sykosch, and Michael Meier. 2020. Towards Detection of Software Supply Chain Attacks by Forensic Artifacts. In Proceedings ofthe 15th International Conference on Availability, Reliability and Security (Virtual Event, Ireland) (ARES ’20). Association for Computing Machinery, New York, NY, USA, Article 65, 6 pages. https://doi.org/10.1145/3407023.3409183
一种基于静态和动态分析的管道,用于检测解释型语言(即 JavaScript、Python、Ruby)中的恶意包。
Ruian Duan, Omar Alrawi, Ranjita Pai Kasturi, Ryan Elder, Brendan Saltaformag- gio, and Wenke Lee. 2021. Towards Measuring Supply Chain Attacks on Package Managers for Interpreted Languages. In 28th Annual Network and Distributed System Security Symposium, NDSS. https://www.ndss-symposium.org/wp- content/uploads/ndss2021_1B-1_23055_paper.pdf
提出了可以从 Java 字节码中观察到的恶意行为指标
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, Olivier Barais, and Serena Elisa Ponta. 2022. Towards the Detection of Malicious Java Packages. In Proceedings of the 2022 ACMWorkshop on Software Supply Chain Offensive Research and Ecosys- tem Defenses (Los Angeles, CA, USA) (SCORED’22). Association for Computing Machinery, New York, NY, USA, 63–72. https://doi.org/10.1145/3560835.3564548
采访了 PyPI 的管理员,以探索此类包仓库的安全目标,并创建了一个基准数据集来评估当前适用于 PyPI 的恶意软件检测工具(例如,Bandit4Mal、OSSGadget)。
Duc-Ly Vu, Zachary Newman, and John Speed Meyers. 2022. A Bench- mark Comparison of Python Malware Detection Approaches. arXiv preprint arXiv:2209.07957 (2022).
SoK: Taxonomy of Attacks on Open-Source Software Supply Chains
2023, Piergiorgio Ladisa, Henrik Plate, Matias Martinez, Olivier Barais, 2023 IEEE Symposium on Security and Privacy (SP)
Key Points
- 107 个开源软件供应链独特攻击向量,以攻击树形式组织
- 关联 94 个真实世界攻击事件,映射 33 项防护措施
- 覆盖开源供应链全阶段(代码贡献→包分发),独立于编程语言 / 生态
- 17 位领域专家 + 134 名软件开发者验证分类法(正确性、完整性、可理解性)
- 防护措施效用与成本评估,识别高性价比措施(如 “保护生产分支”“移除未用依赖”)
Summary
- 本文针对开源软件供应链攻击频发但缺乏通用分类框架的问题,提出了一个独立于编程语言和生态的攻击分类法。研究通过系统文献综述(梳理 183 篇科学与灰色文献)提取 107 个攻击向量,以攻击树形式呈现(按供应链阶段、涉及系统 / 参与者分类),并关联 94 个真实攻击事件与 33 项防护措施。随后通过专家调研(验证分类法结构与完整性)和开发者调研(评估攻击认知与防护使用)验证分类法有效性。最终形成的分类法可支持威胁建模、开发者培训、风险评估等场景,为开源供应链安全研究与实践提供统一参考框架。
Research Objective(s)
- RQ1:构建开源软件供应链攻击分类法 ——RQ1.1 梳理全面的通用攻击向量;RQ1.2 以易懂且实用的形式(攻击树)呈现向量
- RQ2:研究开源供应链攻击防护措施 ——RQ2.1 识别通用防护措施及对应缓解的攻击向量;RQ2.2 评估防护措施的效用与成本;RQ2.3 了解开发者对防护措施的使用情况
Background / Problem Statement
- 背景:开源软件在软件开发生命周期中依赖广泛,但供应链结构复杂导致攻击面大,攻击频发(如 SolarWinds 事件影响 1.8 万用户);工业界(MITRE、OpenSSF)与学术界均在推进供应链安全,但缺乏统一框架。
- 问题:现有研究缺乏独立于编程语言、生态、技术的 “开源供应链攻击通用描述”,无法系统梳理攻击向量、明确防护措施关联关系,难以支撑开发者培训、风险评估等实际需求。
Method(s)
- 系统文献综述(SLR):检索 Google Scholar、IEEE Xplore 等 4 个数据库,经去重、筛选得到 183 篇文献(含灰色文献),提取攻击向量与防护措施,补充雪球抽样扩展来源。
- 分类法与防护措施建模:基于供应链阶段(源码、构建、分发)、系统 / 参与者,采用 “封闭卡片分类法” 构建攻击树(参考 Ohm et al. 2020 的攻击树扩展);按 “控制类型”(指令 / 预防 / 检测 / 纠正)、“参与者” 分类防护措施,映射至攻击树节点。
- 用户调研验证:设计专家问卷(17 人,评估分类法结构、完整性)与开发者问卷(134 人,评估攻击认知、防护使用),采用 Likert 量表与树测试收集反馈。
- 基于前人方法:参考 Ohm et al. 2020 的 “恶意代码注入攻击树”;系统综述方法遵循 Kitchenham et al. 2009、Wohlin et al. 2012 的三步法(规划→执行→报告)。
Evaluation
setup:
| 软硬件环境 | 论文未提及具体实验软硬件配置(研究为分类法构建与调研,无模型训练类实验) |
|---|---|
| CPU | - |
| 操作系统 | - |
| Python | - |
| Crypto++ | - |
| Visual Studio | - |
| Tensorflow | - |
| SKLearn | - |
- 评估方法:分专家验证(树测试验证分类逻辑、Likert 量表评分分类法质量)与开发者验证(攻击向量认知度调查、防护措施使用评估)两类。
- 数据集:183 篇文献(含 94 个真实攻击事件)、专家问卷数据(311 次攻击向量分类任务)、开发者问卷数据(134 份有效反馈);无基线模型(研究为分类法,非模型对比)。
- 实验结果:①专家树测试 75% 分类结果与初始结构一致,82% 认可分类法整体结构,71% 认可攻击向量完整性;②开发者对 “开发新恶意包” 认知最高(90%),“构建阶段注入” 最低(64%),仅 52% 认为自身对 “新恶意包” 有防护;③防护措施中 “移除未用依赖”“版本固定” 使用率最高,“防名称 squatting” 使用率最低。
- 可借鉴:结合文献综述与用户调研验证分类法,确保实用性;不足:未详细披露问卷设计细节(如问题数量、抽样方法偏差控制)。
Conclusion
- 强结论:①提出的分类法涵盖 107 个攻击向量,独立于语言 / 生态,经专家与开发者验证,具备正确性、完整性与可理解性,适用于威胁建模、培训等场景;②33 项防护措施中,“保护生产分支”“移除未用依赖”“版本固定” 效用 - 成本比(U/C)最高,“从源码构建依赖” U/C 最低;③开发者对构建、分发阶段攻击认知不足,防护措施使用率与认知度不匹配。
- 弱结论:①未验证分类法对未来新型攻击的适应性;②未深入分析不同开源生态(如 npm、PyPI)攻击差异的解决方案;③未探究开发者防护措施低使用率的深层原因(如成本、易用性)。
Thought(s)
- 疑问:分类法如何动态更新以适配新攻击技术(如 AI 生成恶意代码)?专家与开发者调研样本量较小(17 人、134 人),结果是否具备行业代表性?
- 可参考方向:①基于该分类法开发针对性检测模型(如针对 “名称混淆”“构建注入” 的深度学习检测工具);②优化低 U/C 比防护措施(如简化 “从源码构建” 流程);③扩展分类法至新兴开源生态(如 Web3、边缘计算开源项目)。
Notes
- 分类法提供在线交互式可视化工具:https://spg.github.io/risk-explorer-for-software-supply-chains/(含攻击向量描述、真实案例、防护措施关联)
- 防护措施控制类型排除 “恢复型”,因研究聚焦 “恶意代码注入预防 / 检测”,不涉及攻击后的恢复流程。
References
攻击树建模参考
M. Ohm, H. Plate, A. Sykosch, and M. Meier, “Backstabber’s knife collection: A review of open source software supply chain attacks,” 2020.

